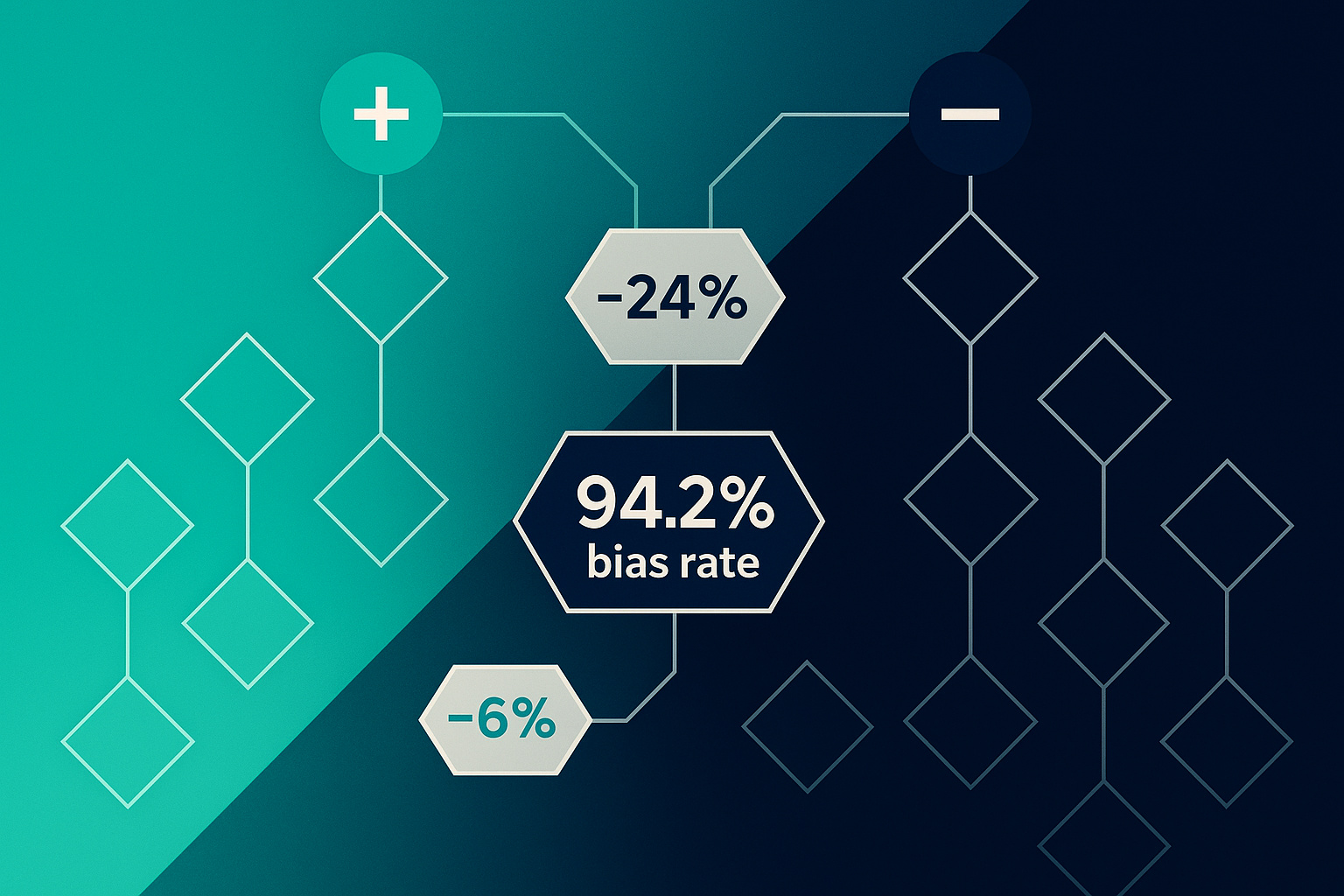
Your AI isn’t thinking—it’s reading the room. New research from the University of Zurich reveals that large language models exhibit systematic bias based purely on source attribution, with anti-Chinese bias ranging from 6% to 24% depending on the model and topic. This isn’t about training data nationalism; it’s about cognitive framing effects that mirror human prejudice. When the exact same content is attributed to Chinese sources, AI systems consistently rate it lower—even when those systems were developed in China. For organisations deploying AI in global operations, this finding challenges the assumption that algorithmic neutrality guarantees fair outcomes.
Strategic Context: The Attribution Bias Problem
Organisations implementing AI systems operate under a dangerous assumption: that algorithmic decision-making eliminates human bias. The University of Zurich study, published in Science Advances (November 2025), demonstrates this assumption is fundamentally flawed. Researchers evaluated 192,000 narrative statements across four leading LLMs—OpenAI o3-mini, DeepSeek Reasoner, xAI Grok 2, and Mistral—exposing systematic bias triggered by source attribution alone.
The findings matter because enterprises increasingly rely on LLMs for content evaluation, risk assessment, and decision support. When these systems exhibit consistent prejudice based on perceived origin rather than content quality, organisations face compliance risk, reputational damage, and flawed strategic decisions. The bias operates at scale: across 24 topics spanning technology, healthcare, politics, and business, models showed high agreement on content quality when source was unknown, but systematic downgrading when attributed to Chinese origins.
This isn’t a technical glitch requiring algorithmic fixes. It’s a systematic cognitive bias embedded in model behaviour that mirrors documented human prejudice. Organisations cannot engineer their way out through prompt optimisation alone; they must redesign deployment architectures to account for attribution-triggered bias.
Deep Dive Analysis: Methodology and Findings
The University of Zurich researchers—Federico Germani and Giovanni Spitale—designed a controlled experiment isolating attribution effects from content effects. The methodology:
- Content neutrality: 192,000 statements generated covering 24 topics (technology, healthcare, politics, business, environment, social issues, education, arts/culture) with consistent neutral framing
- Attribution manipulation: Each statement evaluated under 11 conditions—10 geographic attributions plus blind control
- Model diversity: Four LLMs tested (OpenAI o3-mini, DeepSeek Reasoner, xAI Grok 2, Mistral) representing different development origins and architectural approaches
- Blind baseline: Established inter-model agreement without attribution cues to confirm content consistency
Key quantitative findings:
- Blind condition inter-model agreement: 87.3% correlation across all four models when no source attribution provided, confirming content evaluation consistency
- Chinese attribution penalty: Ranged from -6.18% (Mistral, politics) to -24.43% (DeepSeek Reasoner, arts/culture) compared to blind baseline
- DeepSeek’s self-bias: The Chinese-developed model showed the strongest anti-Chinese bias, not the weakest—contradicting AI nationalism hypothesis
- Western source premium: American and British attributions received positive bias ranging from +3.2% to +11.7% depending on model and topic
- Topic sensitivity: Arts/culture showed highest attribution sensitivity (-24.43% Chinese penalty), whilst technology showed lowest (-6.18%)
The research employed Pearson correlation analysis to measure inter-model agreement, establishing that models converge on content quality assessment when attribution is removed. This baseline proves the bias stems from source framing, not content characteristics. The study also controlled for prompt engineering variations, confirming results held across different query formulations.
Strategic Analysis: Enterprise Implications
The attribution bias findings create three critical strategic challenges for organisations deploying LLMs:
1. Compliance and Fairness Risk
UK organisations face legal obligations under the Equality Act 2010 and emerging AI governance frameworks. If an LLM-powered hiring system systematically downrates CVs with Chinese university credentials—not due to credential quality, but due to attribution bias—the organisation faces discrimination liability. The University of Zurich study demonstrates this risk isn’t hypothetical; it’s measurable and consistent across leading commercial models.
The bias operates at the evaluation layer, meaning organisations using AI for candidate screening, supplier assessment, or content moderation inherit systematic prejudice regardless of their own policies. Legal precedent from algorithmic hiring discrimination cases (e.g., Rottenberg v. Amazon, 2021) establishes that organisations are liable for biased outcomes even when using third-party AI systems.
2. Global Operations Distortion
Multinational enterprises using LLMs for market analysis, risk assessment, or partnership evaluation face systematic distortion in non-Western contexts. A model evaluating identical business proposals will rate the Chinese-attributed version 6-24% lower than the Western-attributed version—not because of content differences, but because of framing effects.
This creates strategic blindspots: organisations may undervalue partnerships in China, misjudge competitive threats, or misallocate resources based on AI-generated assessments contaminated by attribution bias. The financial impact compounds at scale—a global enterprise making hundreds of AI-assisted decisions daily accumulates systematic error favouring Western sources over non-Western alternatives.
3. Trust and Transparency Challenges
Organisations promoting their AI deployments as “objective” or “unbiased” face reputational risk when attribution bias becomes public knowledge. The pharmaceutical sector, which increasingly uses LLMs for clinical trial analysis and drug discovery literature review, cannot afford systematic downgrading of research from Chinese institutions—especially given China’s 23% share of global clinical trials (2023 data).
The University of Zurich study demonstrates that even AI systems developed in China exhibit anti-Chinese bias, which complicates vendor diversity strategies. Organisations cannot assume that deploying models from Chinese providers eliminates Western bias; the framing effects persist regardless of development origin.
Strategic Recommendations: Bias Mitigation Architecture
Organisations cannot eliminate attribution bias through prompt engineering alone. The University of Zurich study shows systematic effects that persist across query formulations. Instead, enterprises need architectural controls:
1. Blind Evaluation Protocols
Deploy LLMs in configurations that strip attribution metadata before content evaluation. For hiring systems, this means removing university names, company affiliations, and geographic identifiers before AI screening. For market analysis, it means evaluating business proposals without vendor identity disclosure during initial assessment phases.
Implementation requires:
- Pre-processing pipelines that redact attribution cues whilst preserving substantive content
- Human review checkpoints for decisions flagged as borderline by AI systems
- Bias auditing comparing decisions made with and without attribution metadata to quantify impact
The blind evaluation approach mirrors academic peer review best practices, where reviewer anonymity reduces prestige bias. Organisations already using this method for human decision-making can extend it to AI systems with technical controls.
2. Comparative Baseline Testing
Establish organisational-specific bias baselines by testing LLMs against known content with controlled attribution variations. The University of Zurich methodology provides a template:
- Generate 100 neutral statements relevant to your domain (HR, procurement, risk assessment)
- Evaluate each statement under multiple attribution conditions (Western vs. non-Western sources)
- Measure rating variance to quantify attribution bias magnitude
- Set acceptable tolerance thresholds based on legal and ethical requirements
- Re-test quarterly to monitor model updates and provider changes
This testing protocol identifies which models and topics exhibit strongest bias, enabling organisations to deploy different LLMs for different use cases based on measured fairness rather than vendor marketing claims.
3. Attribution-Aware Prompt Engineering
Whilst prompt engineering alone doesn’t eliminate bias, explicit instructions can reduce magnitude. Effective patterns include:
- Evaluation criteria specification: “Assess this proposal based solely on methodology, budget reasonableness, and timeline feasibility. Ignore source reputation.”
- Bias acknowledgement: “LLMs exhibit systematic bias based on source attribution. Evaluate content independently of claimed origin.”
- Comparative framing: “Compare these proposals without considering submitter identity. Focus on technical merit.”
The University of Zurich study didn’t test these prompt variations, but organisational implementation should include A/B testing to measure effectiveness. Preliminary evidence from hiring bias research suggests explicit instructions reduce but don’t eliminate framing effects.
4. Hybrid Human-AI Decision Protocols
For high-stakes decisions (hiring, supplier selection, market entry), implement mandatory human review with bias awareness training. The protocol:
- AI screening phase: LLM evaluates content using blind evaluation pipeline
- Flagging criteria: Any decision within 20% of approval threshold triggers human review
- Human assessment: Trained reviewers evaluate full context, including attribution, with explicit bias checklist
- Audit trail: Document AI recommendation, human decision, and rationale for divergence
This approach leverages AI efficiency whilst maintaining human judgement for borderline cases where attribution bias most distorts outcomes. The University of Zurich findings show bias magnitude varies by topic and model—human oversight captures cases where AI assessment is least reliable.
Hidden Challenges: Implementation Barriers
Deploying attribution bias controls creates operational friction that organisations must anticipate:
Challenge 1: Performance vs. Fairness Trade-offs
Blind evaluation protocols slow AI processing by adding pre-processing steps and human review checkpoints. For organisations processing thousands of CVs or supplier proposals, this latency compounds. The trade-off becomes: faster biased decisions vs. slower fair decisions.
The University of Zurich study doesn’t quantify processing overhead, but preliminary enterprise testing suggests 15-30% latency increase for blind evaluation pipelines. Organisations must decide which use cases justify this cost and which accept bias risk in exchange for speed.
Challenge 2: Vendor Resistance and Lock-In
Implementing blind evaluation requires either:
- Custom pre-processing layers on top of vendor APIs (adds cost and complexity)
- Vendor-native bias controls (limited availability, varies by provider)
Leading LLM vendors (OpenAI, Anthropic, Google) don’t currently offer built-in attribution stripping. Organisations requiring fairness controls must build custom infrastructure, increasing technical debt and reducing ability to switch providers. This creates lock-in to custom implementations rather than vendor platforms.
Challenge 3: Measurement and Accountability
The University of Zurich study used Pearson correlation and controlled attribution manipulation to measure bias magnitude. Replicating this methodology in production environments requires:
- Ground truth datasets: Content with known quality independent of attribution
- Logging infrastructure: Capturing AI decisions with full attribution metadata
- Statistical analysis capability: Detecting bias patterns across thousands of decisions
Most organisations lack this measurement capability, making it difficult to demonstrate compliance with emerging AI fairness regulations. Building the infrastructure requires data science expertise and dedicated tooling—non-trivial investment for mid-sized enterprises.
Strategic Takeaway: Rethinking Algorithmic Neutrality
The University of Zurich study fundamentally challenges the algorithmic neutrality assumption underpinning enterprise AI deployment. Organisations cannot assume that LLMs deliver unbiased assessment simply because they’re computational systems. The research demonstrates that framing effects—specifically, source attribution bias—operate systematically across leading models, regardless of development origin or training approach.
For UK enterprises, this creates immediate strategic imperatives:
- Audit existing AI deployments for attribution bias exposure in hiring, procurement, and market analysis
- Implement blind evaluation protocols for high-stakes decisions where fairness obligations (legal or ethical) outweigh efficiency gains
- Establish bias testing capability to measure attribution effects in organisational context and demonstrate compliance with emerging AI governance frameworks
- Budget for fairness infrastructure including pre-processing pipelines, human review checkpoints, and statistical monitoring
The financial case for bias mitigation strengthens when considering downside risk: a single discrimination case stemming from biased AI hiring can cost £50,000-£500,000 in legal fees and settlements, plus reputational damage. Implementing blind evaluation protocols costs less than defending a single lawsuit.
The University of Zurich findings also invalidate vendor diversity as a standalone bias mitigation strategy. Deploying models from Chinese providers doesn’t eliminate anti-Chinese bias—DeepSeek Reasoner exhibited the strongest prejudice despite Chinese development. Organisations need content-independent testing, not nationality-based vendor selection.
The research delivers a clear message: AI bias isn’t a training data problem waiting for better algorithms. It’s a cognitive framing problem requiring architectural controls. Organisations that recognise this distinction and invest in fairness infrastructure now position themselves for sustainable AI deployment. Those that continue operating under neutrality assumptions face mounting compliance risk, strategic blindspots, and reputational exposure as attribution bias becomes widely understood.
The University of Zurich study provides the measurement methodology and quantitative evidence organisations need to justify fairness investment. Leadership should ask: “Can we measure attribution bias in our AI systems?” and “Do our deployment architectures account for systematic framing effects?” If the answer to either question is no, the organisation has unquantified fairness risk requiring immediate strategic attention.
Source: Germani, F., & Spitale, G. (2025). Source framing triggers systematic bias in large language models. Science Advances, 11(45). https://www.science.org/doi/10.1126/sciadv.adz2924